フィーチャーフラグシステムのアーキテクチャー
Table of Contents
tldr
業務で2年以上の社内フィーチャーフラグ & ABテストプラットフォームを開発/運用してきた経験から、フィーチャーフラグシステムを開発するにあたっての考慮すべき点をまとめました。本記事ではフィーチャーフラグシステムのアーキテクチャーについての記事になります。フィーチャーフラグそのものについての概要はこちらの記事を参照してください。
シンプルなアーキテクチャー
まずはシンプルなアーキテクチャーの説明から始めます。VWO, LaunchDarkly, Firebase Remote ConfigなどのSaaSやUnleash、GrowthBookなどのOSSを含め、大体のフィーチャーフラグシステムはフラグ値の動的な変更を可能にするためクライアントとサーバー間で通信が必要になってきます。クライアントからサーバーに対してフラグ値(例 TRUE / FALSE)を問い合わせて、サーバーが値を返却します。システムによりますが、クライアントからはユーザーの属性情報やABテストをする場合はコンバージョンイベントなどを送信します。アプリはSDKまたはWeb APIを通じてフラグ値を受け取り、アプリの挙動をを動的に変更します(例 機能をオン/オフにする)。
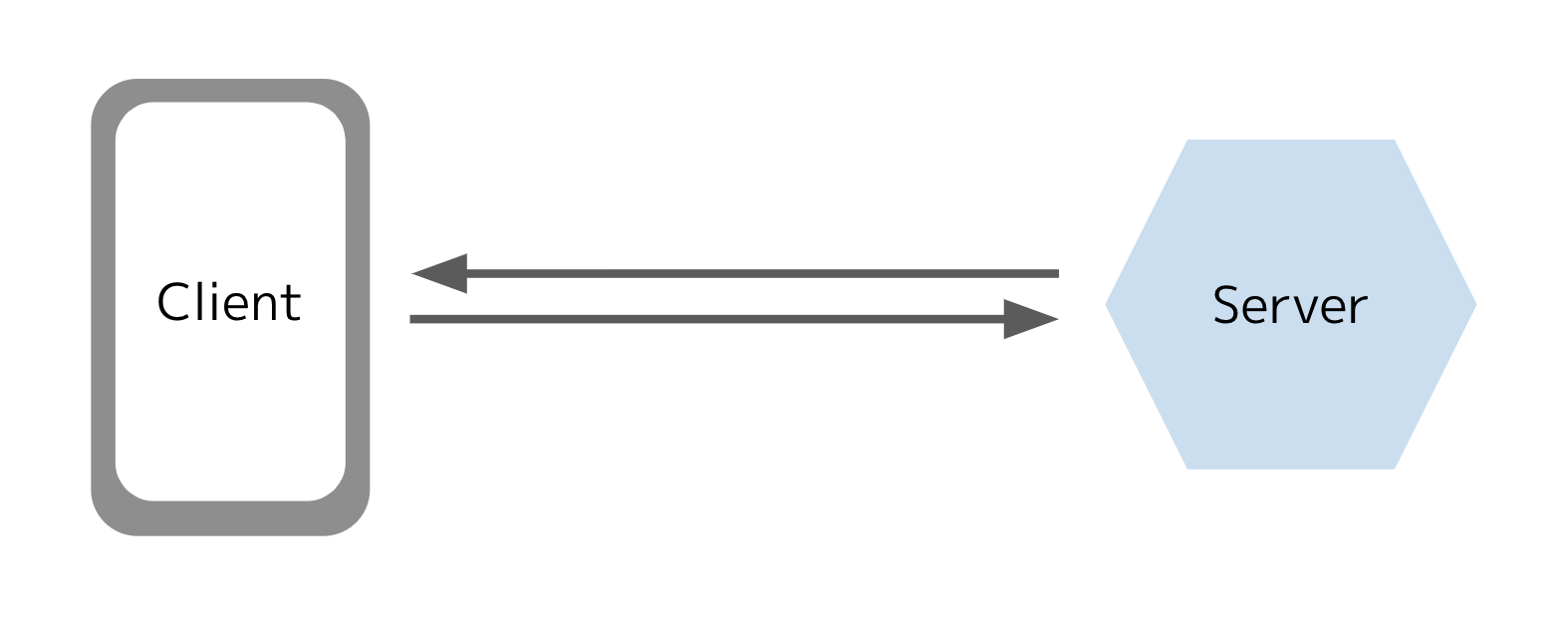
SDK vs. API
フラグ値を返すだけの簡単なシステムの場合、サーバーはAPIを公開するだけで問題ないかもしれません。しかし、他のデータの送受信やクライアント側でのフラグ値のキャッシュ、サーバーに問い合わせるタイミングの調整など、フィーチャーフラグシステムを作り込むにはクライアント側の実装が必要になってきます。そういった場合にSDKの実装が必要になってきます。
実際のところ、SaaSやOSSのフィーチャーフラグシステムではSDKを提供しています。全てのプラットフォームでSDKを提供することはリソース的に難しいのでAPIをシンプルにすることで、ユーザーが独自にクライアント側の実装をすることができます。
どちらの方法にしろ、フラグ値の取得部分はフェイルセーフに作っておく必要があります。通信の切断やその他思わぬトラブルでSDKに問い合わせたフラグ値が正常に取れなかった場合、デフォルトの値をアプリに返すようにしておかないとアプリが予期しない挙動を起こす可能性があります。
フラグ値の決定ロジック: クライアント vs. サーバー
フラグ値の決定とはクライアントの情報をもとに、フラグのフラグ値を決定するプロセスのことをいいます。例は以下のようなものです。
- クライアントアプリのバージョンが v1.2.1 以上の場合はTRUEを返す
- ユーザーIDをもとに生成したハッシュ値を100で割ったときの剰余が <50 だったのでTRUEを返す
上記の例のように、フラグ値の決定ロジックにはクライアントの情報とフラグ情報の両方が必要になることが多いです。そのため、サーバーからフラグ値を取得してクライアント側でフラグ値を決定するか、クライアントからクライアント情報を取得してサーバー側でフラグ値を決定するか、どちらかになります。
クライアント側
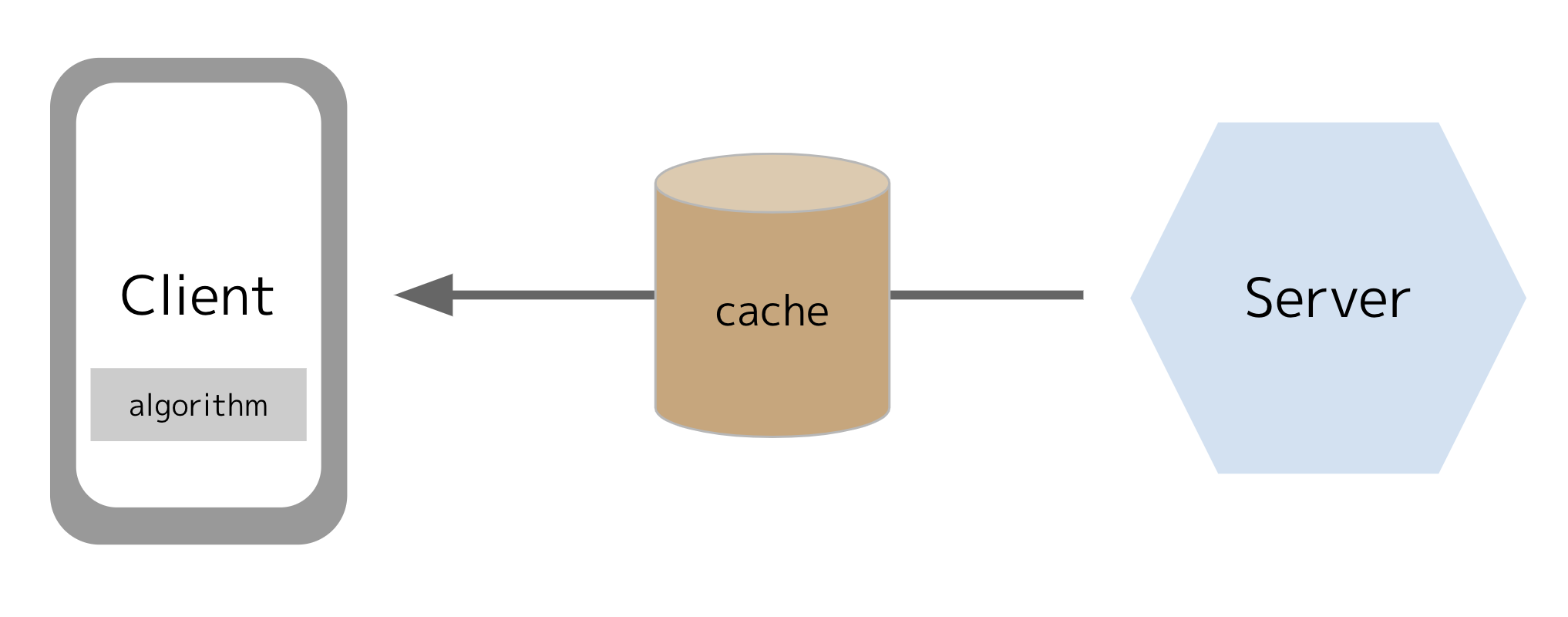
クライアント側でフラグ値を決定する大きな利点はスケールしやすい点です。クライアント側にロジックを置くので、サーバーはフラグ値を返すだけでよくなります。そのため、フラグ値をキャッシュ層やCDNから返すことができ、低いコストでスケールできるアーキテクチャーになります。また、プライバシーの問題からユーザー属性情報をサーバーに送信したくない(できない)場合にもクライアント側にロジックを持っていれば問題ありません。
デメリットとしてはクライアント側の実装が大変になることです。10種類のSDKを提供しているサービスはそれぞれフラグ値の決定ロジックを実装する必要があります。たいていの場合、フラグ値の決定ロジックはとても重要かつ(ユーザーからの要望により)難しくなりがちです(ユーザーの属性情報の判定や段階的ロールアウトへの対応など)。ロジックの変更はユーザーがクライアントアプリをアップデートして初めて提供されます。
サーバー側
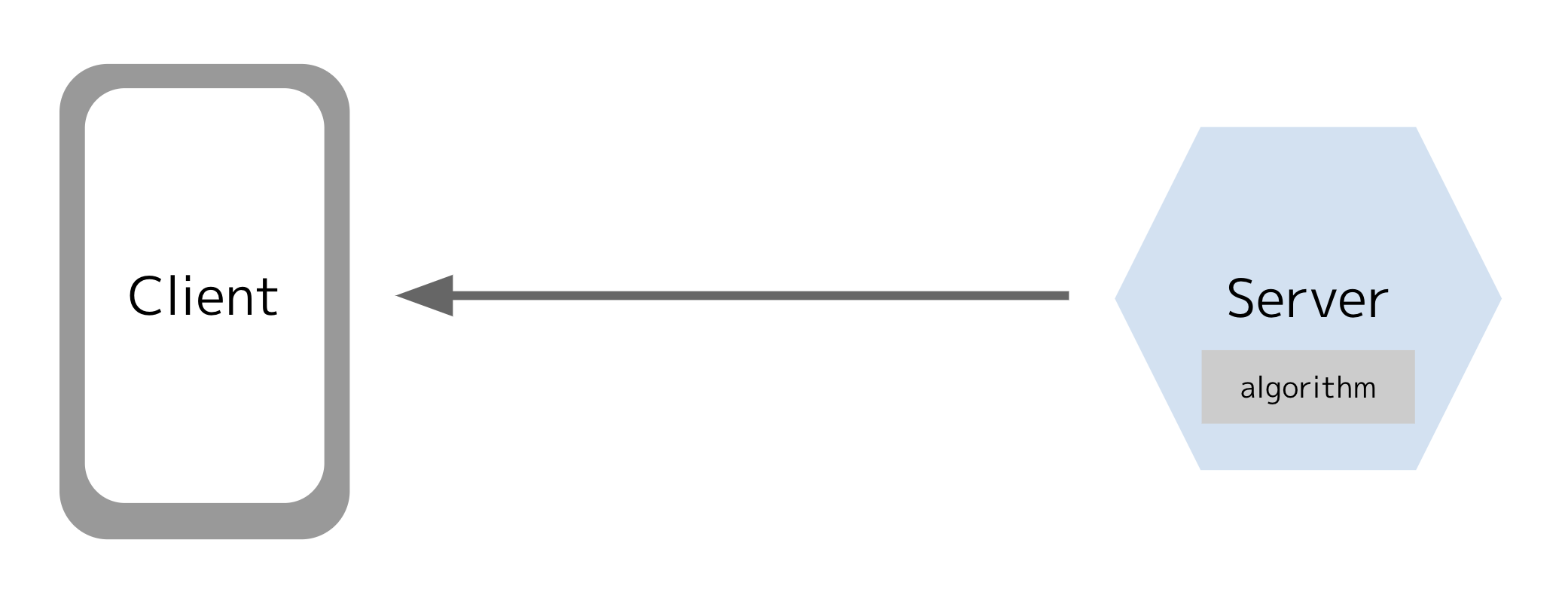
サーバー側にフラグ値の決定ロジックを持ってくる利点の一つはSDKがシンプルになることです。ロジックは1箇所のみに記述され、変更はサーバーをリリースすれば完了します。外部のサービスを使用してフラグ値を決定する(例えば、社内の独自のサービスを使ってユーザーのデモグラを判定する)ことも比較的容易に可能です。
クライアントのメリットがそのままデメリットになります。サーバーは1リクエストごとに決定プロセスを処理しなければならず、スケールにコストがかかります。また、ユーザー属性情報を送らないクライアントに対しては細かなルールを設定することができないかもしれません。
フラグ値の変更: プル vs. プッシュ
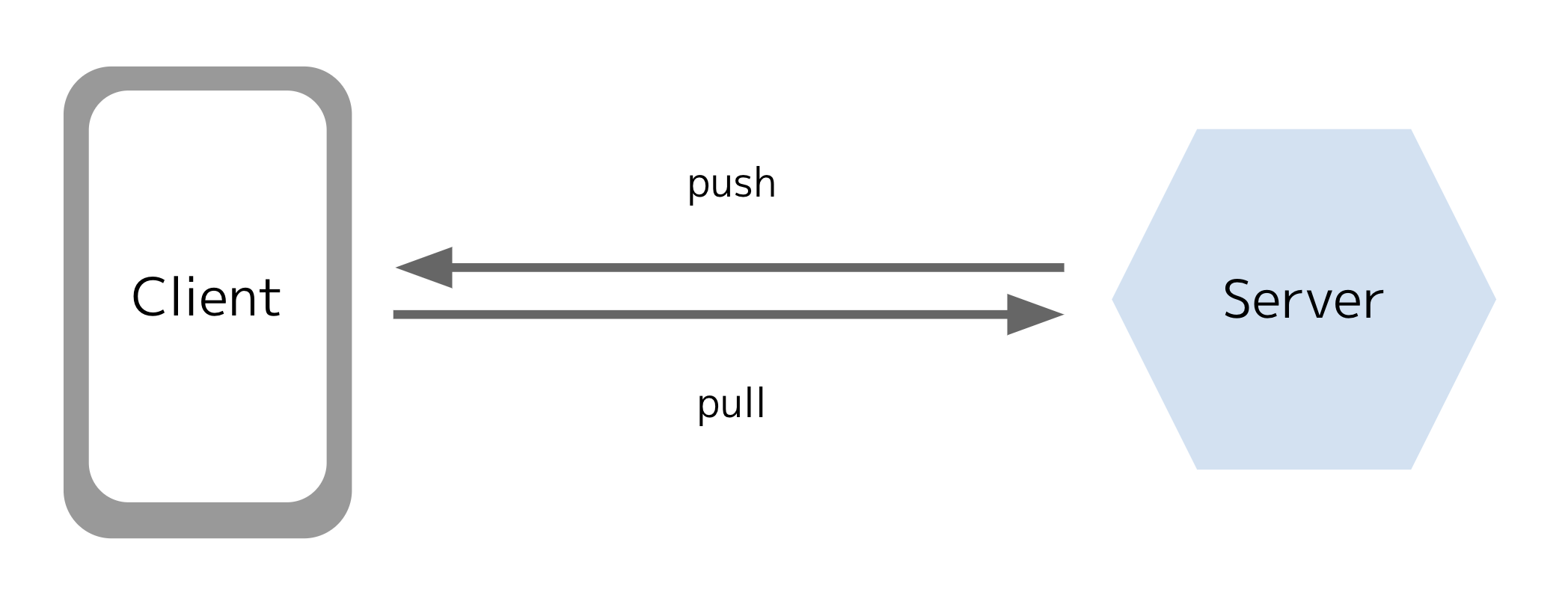
多くのフィーチャーフラグシステムはコンソールUIが容易されており、アプリ開発者が動的にGUIを通じてフラグ構成を変更することが可能です。それに加えて一部のシステムはJSON APIやWebhookを通してフラグに対する変更を自動化することもできるようになっています。サーバー側で変更されたフラグ情報はどのようにクライアントに反映させるのでしょうか?
プル
1つはクライアントが定期的にサーバー側に問い合わせを行う方法です。決められて時間毎にクライアントはサーバーからフラグ値を取得し、アプリでフラグ値を使用します。この方法のメリットは実装がシンプルになる点です。クライアントはリクエストを行い、取得した情報をメモリやローカルストレージに保存して使用します。動的に変更されたフラグは次回の取得時に更新されます。デメリットはクライアントに不必要なリクエストをさせてしまう点です。フラグ情報の変更は大規模なアプリでない限り、実際にはそこまで頻繁に行われません。取得する情報が変わらないのに、数分ごとにリクエストをするのはあまり良くはありません。もう一つのデメリットはフラグの変更が即時クライアントに反映されないことです。例えばエラーレートを監視して問題があった際に該当する機能を落としたい場合、クライアントでのフラグ値の変更までの時間イコール障害発生時間になります。開発者としてはできるだけ早く機能をオフにしたくても次回クライアントがリクエストしてくるまでできません。
プッシュ
フラグ情報をクライアントに反映させるもう一つの方法はサーバーからフラグ値をプッシュする方法です。プッシュ通知やwebsocketなどを使ったサーバー起因の通信がこれにあたります。プッシュ方式の良い点はフラグ情報を反映させる速度です。GUIなどでフラグ情報を変更すると、早ければ数ミリ秒でクライアントのフラグ値を変更可能です。プッシュされるのはフラグ情報が変更されたときだけなので、無駄な通信をすることもありません。この方法のデメリットは実装がプル方式に比べて複雑になることです。また、websocketなどで実装する場合はクライアントとサーバー間でコネクションを張っておく必要があるためある程度のリソースが常時必要になります。
まとめ
フィーチャーフラグシステムを設計するときには考慮すべき点がたくさんあります。上で書いたトピックはどちらがいつも正しいものではなく、システムを使用するプロダクト、開発者、組織、リソースなどによって適宜判断されるものだと考えています。実際私も今のチームの状況とプロダクトの成長具合を鑑みながらより少ないリソースでより大きな価値を提供できるか考えながら開発を行っています。次はABテストについて書けるといいなー