大規模データ分析DB Druid
Table of Contents
tldr
Apache Druidの概要とメリット・デメリット、実際導入したときのの構成を説明します。
Druidとは
大規模なイベントデータのリアルタイムなクエリを可能にする分散型DBです。BIとかOLAP(OnLine Analytical Processing)と呼ばれる分野で使用されたりします。 類似プロダクトはBigQueryとかになります。
2011年から開発が始まり、現在はApache Licenseで開発が続けられています。
Druidの特徴
ユースケース
Druidにフィットするユースケースは大量のイベントデータをリアルタイムに解析するような場合です。 公式ページには例として以下のようなケースが挙げられています。
- ウェブおよびモバイルの行動分析
- リスク/不正行為の分析
- ネットワークパフォーマンスモニタリング
- サーバーメトリクス
- サプライチェーン・アナリティクス(製造業メトリクス)
- アプリケーション・パフォーマンス
- ビジネス・インテリジェンス/OLAP
分散型DB
Druidは分散型DBであり、複数のコンポーネントが協調して動作します。 それぞれのコンポーネントを異なるサーバー上で動かすことが以下のようなメリットがあります。
- 負荷が高い/低いコンポーネントのみリソースを調整可能
- 冗長構成や並列処理が前提となっている
後述しますが、Kubernetes上でそれぞれ別のDeploymentとして動かすことが可能です。
列指向DB
データは列ごとに圧縮されて保存されます。そのためクエリで必要な列のみに検索をかけることで処理を高めています。 Druidは時系列データベースのため、各行のプライマリキーは時刻になります。
信頼性
Druid信頼性やスケーラビリティを担保することを前提に設計されています。
- どのような理由であれ、ダウンタイムなしに継続的に動作する。
- これは構成の変更やソフトウェアの更新にも当てはまります。各コンポーネントはローリングアップデートされ、ダウンタイムなしでアップデートできる。
- データのレプリケーションに対応しており、1つのサーバーで障害が起きても問題なくサービスが提供できる。
- データはディープストレージと呼ばれるディスクにバックアップされ、いつでも復元が可能。
アーキテクチャ
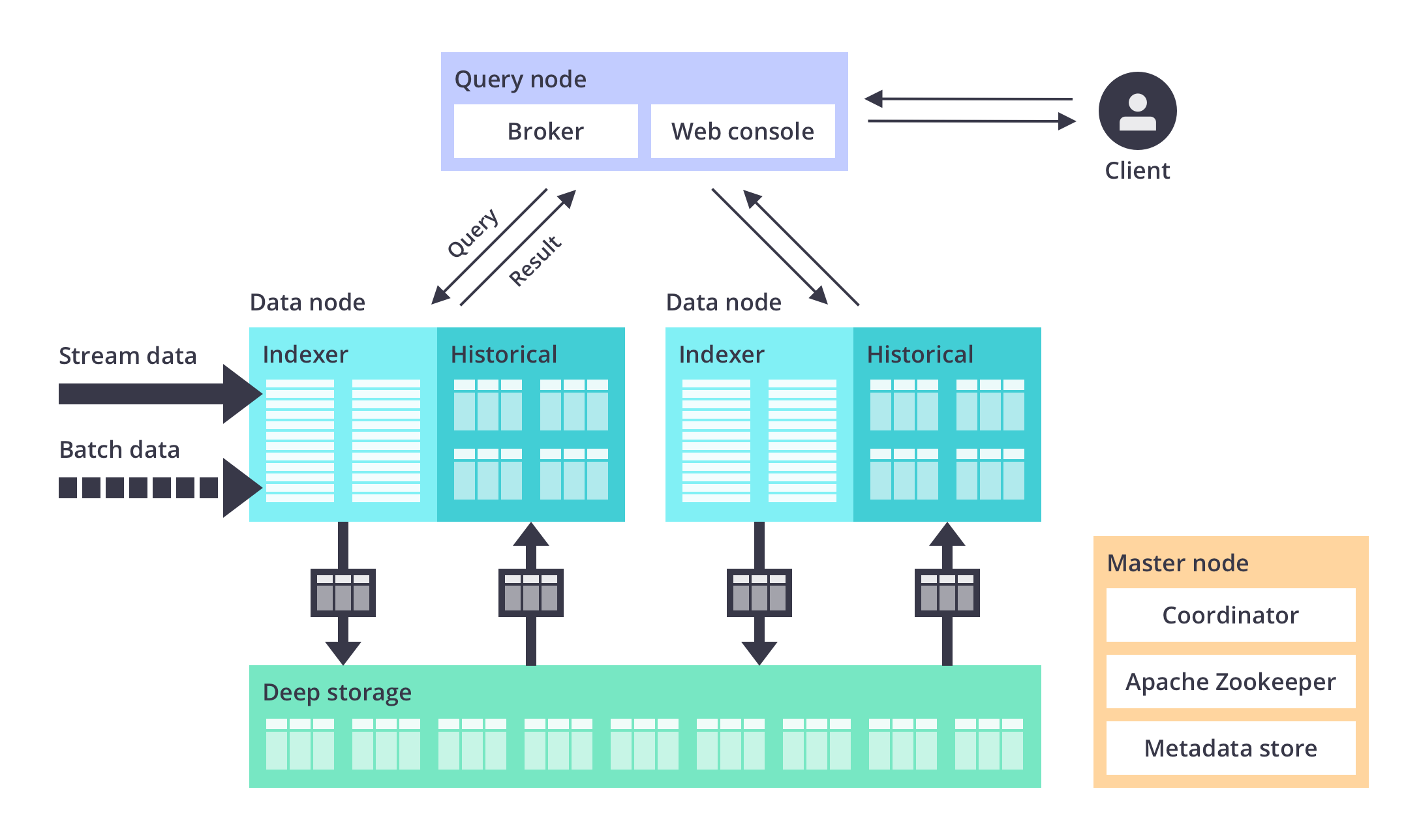
Druidは上記の図のようなアーキテクチャになっており、各コンポーネントは3つのカテゴリに分けられます。
- データノード: イベントデータを受け取り、処理する
- クエリノード: データのクエリを処理する
- マスターノード: 各コンポーネントやタスクを管理する
データノード
データノードは
- Middle manager または Indexer
- Historical
から構成されています。
データノードの処理は以下の通りです。
- Middle manager(もしくはIndexer)がバッチまたはストリームからデータを受け取る
- データを処理してディープストレージにセグメントデータとして保存する
- Historicalがディープストレージからセグメントを自身のディスク上に展開する
データ取得のインテグレーションは様々用意されており、Kafka, KenesisといったストリームからHadoopからバッチ処理で取得することもできます。
ディープストレージはローカルディスクだけでなく、いくつかの拡張プラグインが用意されおり、GCSやS3といったよりパブリッククラウドのストレージサービスにすることも可能です。
執筆時点での対応ストレージは以下になります。
- HDFS
- Microsoft Azure
- Google Cloud Storage
- AWS S3
- Aliyun OSS
- Apache Cassandra
- Rackspace Cloudfiles
- Microsoft SQLServer
クエリノード
クエリノードは
- Router
- Broker
から構成されています。
- Router(Druidの純正ウェブコンソール)もしくは外部サービスからクエリリクエストがBrokerに送られる
- Brokerはクエリを解釈しIndexerとHistoricalに向けてクエリを送信する。
- リアルタイムデータ(セグメントとしてまだHistoricalに展開されていないデータ)はIdexer, セグメントデータはHistoricalが処理をしてBrokerに返却する
- Brokerが各結果をマージしてクエリ結果を返す
マスターノード
マスターノードは
- Coordinator
- Zookeeper
から構成されており、Druid内のメタデータやタスクデータの保存や管理を行っています。
クエリ
Druidのクエリには
- SQL
- Native
の2種類のクエリ言語が用意されており、NativeクエリはSQLより柔軟かつやれることが多いです。SQLクエリはNativeクエリに変換されて処理されます。
集計 Aggregation
Druidのクエリの特徴として、ビルトインで様々な集計クエリが提供されている点があります。
- count
- sum
- min/max
- first/last
また、JavaScriptによるカスタムアグリゲーションもクエリに組み込めます。
近似的なクエリ
正確なカウント数や統計量を出すには計算時間とメモリを大量に使うことになりますが、Druidは近似的にそれらを計算するアルゴリズムが備わっています。例えば、以下のようなものです。
- ユニークカウント(カーディナリティ)
- ヒストグラム
- Quantile
Post aggregation
さらに、集計した値を更に集計にかけることも可能です。 以下のクエリ(一部)はpost aggregationでパーセンテージを計算するシンプル例です。
{
...
"aggregations" : [
{ "type" : "doubleSum", "name" : "tot", "fieldName" : "total" },
{ "type" : "doubleSum", "name" : "part", "fieldName" : "part" }
],
"postAggregations" : [{
"type" : "arithmetic",
"name" : "part_percentage",
"fn" : "*",
"fields" : [
{ "type" : "arithmetic",
"name" : "ratio",
"fn" : "/",
"fields" : [
{ "type" : "fieldAccess", "name" : "part", "fieldName" : "part" },
{ "type" : "fieldAccess", "name" : "tot", "fieldName" : "tot" }
]
},
{ "type" : "constant", "name": "const", "value" : 100 }
]
}]
...
}
実際の構成例
一例として、私が所属しているチームではDruidの構成は以下のようになりました。
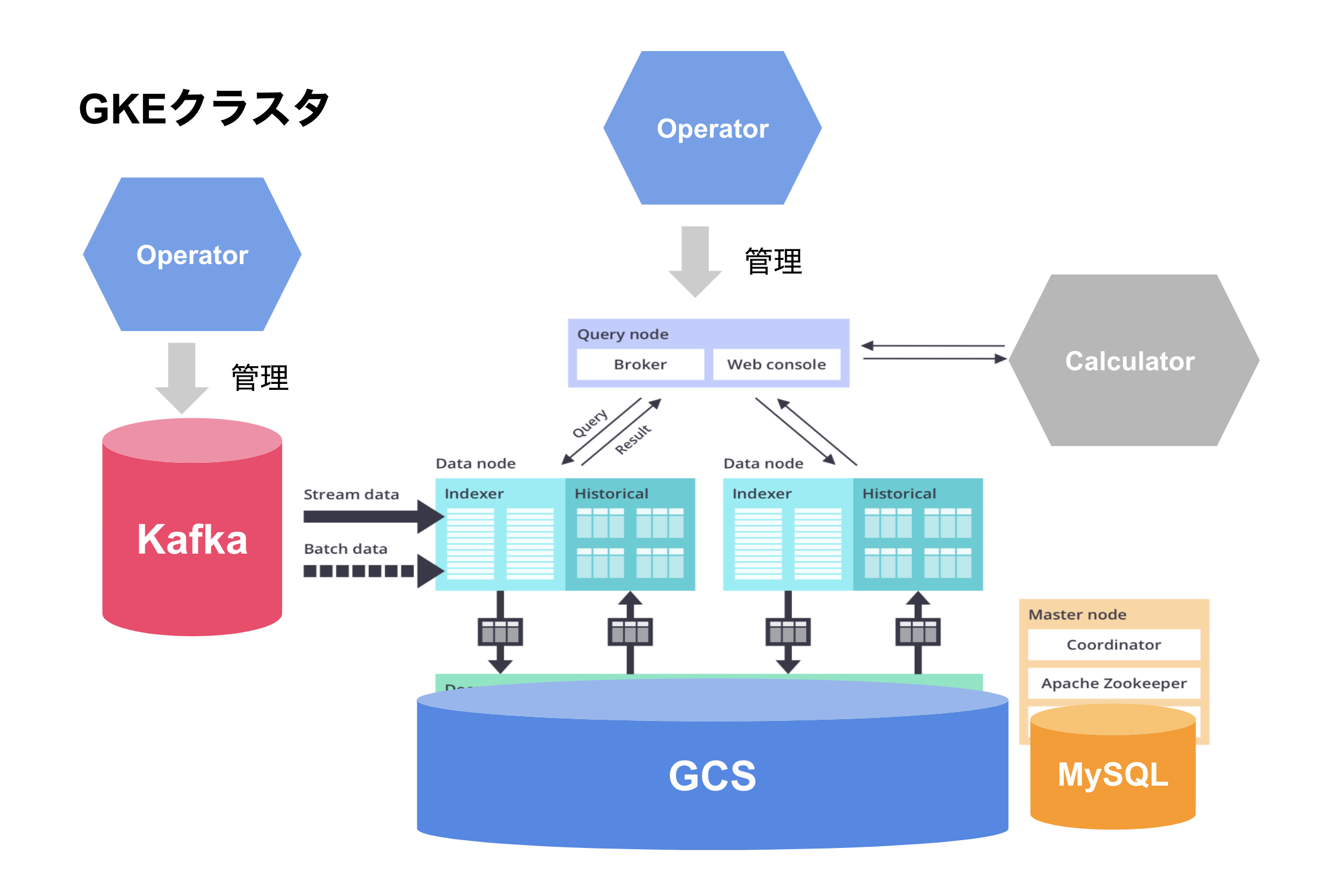
- GKE上でDruid Operatorを使って、クラスタをデプロイ
- Zookeeperをhelmを使用してデプロイ
- メタデータストレージにはCloud SQL(MySQL)を使用
- ディープストレージにはGCSを使用
- クラスタ内にStrimziを使用してKafakクラスタをデプロイ
- KafkaからDruidへデータをストリームで流す
- クエリはGoのサービスがライブラリを使用してクエリする
困ったところ
チューニングが難しい
大量のデータを処理するために使用することもあり、特にデータを処理するMiddle managerやクエリを処理するBrokerのリソースを慎重に考える必要があります。DruidはJavaで書かれているので、JVMの最低限の知識も必要になります。
Cloud Pub/Sub対応してほしい
執筆時点ではGCPのCloud Pub/Subからのデータ取得には対応していません。PRはあるのですが、何ヶ月も止まったままになっており優先度が高くないようです。
開発が活発なGoライブラリがほしい
PythonやJavaなどのライブラリは活発に開発が続けられていますが、Goのこれといったライブラリが存在しません。 なにか出てきてほしい。
まとめ
Druidは大規模なデータをリアルタイム分析しなけれいけないケースで有用です。 Kubernetesで運用も比較的簡単でOperatorも公式から用意されています。チューニングなど、いくつか乗り越える壁はありますが、フィットするプロダクトは多くありそうです。 この記事がDruidを試してみようかなと思う方のお役に立てたら幸いです!